Five Concerns in Ethical and Responsible AI (and how most tech companies fall short)
Wondering why some people are saying that most current AI tools (especially generative AI) weren't developed ethically or responsibly, why it matters, and what you can do? This deep dive is for you.
We’ve all been swamped by hype around generative AI tools in the past few years. It’s been easy to miss other voices pointing out urgent concerns about how the tools are built, how they’re used, and who they are helping or harming. These issues are increasingly breaking through nowadays, surfacing in discussions about “ethical AI”, “responsible AI”, or “trustworthy AI”.
If you’ve been using generative AI tools like ChatGPT, Gemini, Claude, & Perplexity, and wondering why AI ethics are a concern, here’s the scoop. This article looks in depth at the pluses and minuses of ethical and responsible AI in development and use of AI-based tools. I highlight why more and more people view most current AI tools — especially generative AI tools — as unethically developed. Learn what you didn’t know you didn’t know about how AI tool ‘sausage’ is made; why these ethical concerns matter; and what you can do.
6 'P's in AI Pods (AI6P) is a 100% reader-supported publication. To receive new posts and support this work on ethical AI, consider becoming a free (or paid) subscriber.
This article is not a substitute for legal advice and is meant for general information only.
Overview
“Generative AI was trained on the internet and so has inherited many of its unsolved issues, including those related to bias, misinformation, copyright infringement, human rights abuses, and all-round economic upheaval.” 1 [MIT Technology Review, 2023]
Training & Reference Data - ethical sourcing for AI training, and ensuring users don’t feed unauthorized data into the AI tool during operations
Traceability & Fair Use - transparent labeling and ‘data provenance’: knowing if an output was generated with AI, and knowing what data was used to generate it
Bias Minimization - detecting and mitigating biases in acquiring and using data
Cost-Benefit Analysis - environmental impact and how use of AI impacts people and society
In the past 8+ months, we’ve learned more about ethics in development of AI tools, particularly about exploitation of data workers as part of data sourcing. We’ve also learned more about recent impacts of generative AI on people’s lives and livelihoods in domains other than music. While this article examines the same issues as the 4 pillars, I’ve regrouped the concerns to reflect what we’ve learned and to broaden the scope beyond music.
The diagram in Figure 1 shows 5 key steps in the AI development & use ecosystem, and how the 5 steps map to 5 ethical AI concerns. 3 Arrows from the 5th step, “AI Tool Usage”, go back to the first 4 steps to highlight that people who use AI-based tools and systems: (1) Generate more workload to drive demand for data centers; (2) Contribute new data for use in the tools, through their prompt details and uploads; (3) Donate data enrichment labor, e.g. by tagging or labeling content the tool shows; (4) Provide model tuning data and labor (via RLHF, or Reinforcement Learning from Human Feedback), through their responses to what the tool generates for them.
For each of these 5 steps, I’ll briefly explain the associated ethical concern, where the opportunities and problems lie, and the current status of the world, along with some example references (of so many out there!) for further reading.
All 5 concerns are ongoing topics in this 6 'P's in AI Pods (AI6P) newsletter. They apply to all types of AI and machine learning, not just generative AI. To be notified of new articles on AI ethics and join our conversations, we invite you to subscribe (free):
Five AI Ethics Concerns
The 5 ethical concerns covered in this article [mapped to the original 4 pillars] are:
AI algorithms need data and computing power. Inefficient algorithms or wasteful use of AI will drive demand for even more data, power, or both.
Environmental and climate impacts are a key factor in cost-benefit analyses of AI technologies, especially generative AI. The concerns encompass use of limited water and ‘rare earth elements’, creation of hazardous wastes like lead and mercury, high energy usage for cooling and computing, and CO2 emissions.
Managing and meeting power demands for AI present additional concerns.
1a. Opportunity
AI (mostly not generative AI) has the potential to help humans find more efficient ways to design and operate all kinds of systems. This includes intelligent controls and real-time analytics to address climate, cooling, power, and safety challenges. AI could also be used to help identify more efficient or effective algorithms for performing AI itself.
1b. Problem
Current AI algorithms and systems need massive data centers.
Building data centers requires mining of ‘rare earth elements’, consumes water, and creates hazardous wastes like lead and mercury.
During operations, data centers consume even more water for cooling, and demand high amounts of energy. (For example, queries to generative AI tools like ChatGPT can take 10x more computing power than a web search on the same topic.)
You may have heard buzz about AI training costs. While they can be steep, people’s high levels of AI tool usage (‘inferencing’) actually consume far more power and water than training.
All of this energy consumption impacts CO2 levels. This 2022 post led by Dr. Sasha Luccioni, the AI and Climate lead at HuggingFace, explains why CO2 emissions from AI matter.4
Simply providing the huge amounts of power that these AI data centers require has raised new concerns. AI companies have taken steps to reactivate old nuclear power plants (e.g. Microsoft and Three Mile Island 5 - the site of a partial meltdown in 1979, and the worst nuclear disaster in U.S. history 6). Other companies (e.g. Google, Amazon, and Meta7) are pushing hard towards use of ‘SMRs’, or small modular nuclear reactors. As a result, AI power demands are reviving environmental concerns relating to nuclear power costs, risks, and waste.
1c. Status
AI-driven explosion in use of these globally scarce resources has only recently been monitored. As one example, Dr. Luccioni helped to develop the open source Python project CodeCarbon which is designed to help with measuring the carbon footprint of code. Her July 2024 podcast on this topic characterized generative AI as “a climate disaster”. 8 Some major AI companies have reported on AI impact and CO2 emissions as part of their global Corporate Social Responsibility initiatives, although momentum and focus seems to be fading recently.
Additionally, the shift towards SMRs brings heightened concerns about their safety and waste: being smaller doesn’t mean they are safer or more efficient. 9 In fact,
“experience suggests that these reactors will not be cheap and will contribute to problems like radioactive waste generation and the potential for nuclear weapons proliferation and risk of severe accidents.” 10
SMRs also carry distinct cybersecurity risks 11. However, research studies are ongoing in China that examine possible “mutual benefits” between AI and SMRs. 12
Most of the focus has been on the supply-side struggle to meet the rising demands for power and computing power. Far less attention has been paid to reducing these demands by finding and encouraging ways that:
people can use AI tools more judiciously or more efficiently, or
developers can make AI itself more efficient.
At this writing, AI-driven demand for computing and power shows no signs of abating. AI companies have made little or no effort to modulate demand for their tools, e.g. by encouraging more selective and efficient use of generative AI tools. This isn’t surprising, really: both startups and well-established enterprises are generally incentivized to show their stakeholders and shareholders increasing numbers of users and uses every fiscal quarter that will drive increased stock valuations and profits.
To date, large AI companies have mostly not prioritized efforts to manage environmental impacts by finding more efficient AI algorithms. A notable exception that caught attention in early 2025 is DeepSeek. Debate over its actual energy efficiency in training and inferencing is ongoing. 131415
Researchers are also pursuing ways to reduce CO2 impact of generative AI, such as:
By moving data center workloads around so they are executed at more sustainable sites16. One such study claims to show the potential for up to 56% improvement in CO2 impact in the future 17.
Exploring how AI, ML [machine learning], and DL [deep learning] can enable increased carbon capture in real-time industrial automation systems 18.
Evaluating whether plug-in electric vehicles and V2G (Vehicle To Grid) technologies can help to mitigate the impact of genAI workloads. 19
Nonetheless, the bulk of research attention and corporate funding has gone into expanding the power and use of AI, amplifying the voracious appetite for these critical resources. Resourcing for public funding of research on using AI to tackle environmental challenges is also at increased risk in the USA these days.
References for Concern 1: 4-19 inline above,20 (UNEP), 21 (Nature).
AI tools are developed (trained) and run on massive amounts of data. This can include written texts, images, videos, or other ‘modes’ of data. Where does it all come from?
Simply, most data comes from humans! In most regions of the world, laws or mores support people’s ownership rights to their data. And most people believe they have inherent rights to the “3Cs: Consent. Credit. Compensation.” 22 for the use of data they own. However, ownership rights can get complicated when people’s data is:
stored in online platforms that tech companies control,
released under a legal agreement (e.g. a contract between a musician and a label),
collected from people without their full, free, and informed consent.
Many questions have arisen on whether companies who obtain data for AI are sourcing it ethically - i.e. whether people are given a fair chance to give or withhold consent; whether they are credited; and whether they are compensated.
2a. Opportunity
Creative people who have large bodies of existing work could potentially make more money from it by licensing the rights to their data:
to AI tool companies for model training and development, and/or
to people to use as additional inputs for AI tools.
Additionally, creators from marginalized communities might be able to provide urgently-needed data that diversifies the training datasets used by AI tool companies. This could improve representation of their communities and enhance the ability of an AI model to generate less-biased outputs that reflect our diverse world.
Beyond the issue of consent, there are many ways that creators could be credited and compensated for use of their works.
The most direct way is building traceability of data sources into the AI system from the beginning. In some cases, with existing tools that have already been extensively trained, retroactive tracing may not be feasible.
Another way is to determine after the fact which parts of the training data were used in generating an output, and base compensation to creators on that analysis. [proposed by AISW interview guest #045, Devansh23, among others]
Still another way is to compensate creators as a community or group when traceability to individual works is truly infeasible. [proposed by AISW interview guest #034, Anyela Vega24, among others]
2b. Problem
The vast majority of major AI tools, and many minor tools, have been built on stolen data. The companies may call it ‘scraping’ or ‘harvesting’, or claim that it’s ‘fair use’ of ‘public domain’ data. Sometimes they will point to a well-known repository that someone else built in the past for ‘research’ purposes. But usually the companies are knowingly taking data that other people (not them) legally and morally have the rights to — rights that those people did not choose to give up for business use.
Using research data for commercial purposes is unfair to the people who consented to sharing it for research only. And just because data is ‘publicly available’ (I can access it over the internet) does not mean it is truly ‘public domain’ and free for me to use as I wish. Many well-known repositories and tools have been built upon stolen content, e.g. scraped YouTube videos 25 or pirated books (82tb 26 ).
Making matters even worse, some repositories used for AI training, e.g. LAION-5B, are known to be polluted with harmful content, such as CSAM material 2728. This allows unethical people to generate even more horrible, exploitative content.
In addition to the ethical risks, people and companies who rely on AI-based tools which were built with stolen or polluted data may be unknowingly taking legal risks by using what they generate with those tools.
2c. Status
A small percentage of companies are transparent about where they get their data:
Anthropic recently announced ISO-42001 certification to confirm that their Claude genAI tool was fairly sourced.
While researching my 2024 article series on generative AI for music, I found some uncertified companies who appear to be sourcing and developing their AI tools ethically. 29
Unfortunately, these companies are the exceptions - not the rule. Most large AI tool companies are deeply sunk in their use of unethically-sourced training data. To date, they show no intentions of trying to put on the brakes, let alone reverse course. And once an unfairly trained, biased, or polluted dataset is released to the public, there’s no practical way to claw it back from whoever already accessed and copied or used it.
On the legal side, some social media platforms and collaborative tool sites have begun changing the terms and conditions for use of their websites to claim that customers are consenting to use of their data for the company’s AI models. 30 In regions which do not have strong data protection regulations, opt-outs are often not offered, or are not effective or useful.
However, competitive tools and platforms are emerging which commit to not train AI models or exploit people’s content without their consent. Examples include Cara and Foto. Adobe claims that for its latest AI tool, Firefly Video Generator, they only used licensed data and true ‘public domain’ data for training. 31
Other initiatives are emerging to address the challenges of traceability and transparent labeling - knowing if AI was used to develop an output, and knowing or determining what data sources were used to generate it. For example:
Voice-Swap and BMAT announced in May 2024 that they are developing ways to tell if a generated song was based on copyrighted content.
In some of the active US lawsuits on AI-driven copyright violations (39 at this writing), the plaintiffs claim to show clear traceability of AI tool outputs to the copyrighted songs they were based on.
Perplexity.AI has won kudos for its ability to provide direct citations for the content it generates. For research, especially, this is a win 32 . It’s great for everyday users too 33. However, ethicality of Perplexity’s data sourcing has been questioned (see Michael Spencer’s comment on Alex McFarland’s guest article).
In late January 2025, Anthropic announced a ‘citations’ feature for Claude to enable it to include sources to back up what it generates.
Tech firm IQIDIS has developed a hybrid approach that eliminates the risk of erroneous citations for their legal AI platform. (See the interview with
In support of transparency in AI tool usage, the Content Authenticity Initiative is creating a “secure end-to-end system for digital content provenance with open-source tools and a cross-industry community of adopters”. They are developing “open-source tools for verifiably recording the provenance of any digital media, including content made with generative AI.” However, full traceability of source content used in generative AI tools is outside their scope.
Traceability to source citations enables crediting the creators of those materials, and potentially compensating them. Of more importance to AI tool users, traceability helps to reduce so-called “hallucinations” (mistakes or lies) which have plagued generative AI since it became popular.
As a defensive measure, AI-based ‘poisoning’ tools are emerging to help creators protect their work from being misused by an AI tool without the creator’s consent. Examples include Nightshade and Glaze from the University of Chicago and Kudurru from Spawning.ai34.
Raw data generally needs extensive processing to be used for training AI and in operations of AI-based systems. While much of the data processing is automated, some isn’t, and human labor is needed to make the data and tool useful.
3a. Opportunity
Data ‘enrichment’ work is critical for using AI for training and in operations. It has the potential to offer people in job-scarce areas remote work opportunities to support themselves and their families. Many AI companies engage data workers directly or through an outsourcing company.
3b. Problem
Workers can be exploited through unfair wages and working conditions. Some data enrichment work involves labeling or classifying violent or abusive content for hours, which can severely degrade workers’ mental health.
“Companies can be unethical about employing data labelers in (at least) two big ways:
Exploitative underpayment, overworking, and general mistreatment of workers
Requiring workers to review and label volumes of horrific, violent, or degrading content, without regard for the emotional health and well-being of the workers”35
3c. Status
Transparency on how companies handle data enrichment work is still poor. Some reported cases of worker mistreatment seem to have been addressed. Others have been disguised by companies shifting the work to an outsourcing company, then disclaiming responsibility for how the workers are treated. A recent 60 Minutes deep dive reported on data workers in Kenya in the documentary “Human Loop: Training AI takes heavy toll on Kenyans working for $2 an hour” on YouTube. 36
Existing and emerging standards for AI and data ethics (such as mentioned in concern #3) do not yet directly address fair treatment of data workers.
Biases permeate our society and our lives; 12 common types are recognized. 37(Example: biased performance feedback on the job 38.) Social biases are flawed patterns of thought that result in unfair or incorrect social assumptions and judgments, reducing social intelligence. Many social biases are ‘unconscious’ or implicit; 19 types have been identified. 39
4a. Opportunity
Some tools have been developed to help people identify their own biases, such as the free suite of 18 Implicit Association Tests from Harvard project “Implicit”. 40
Well-trained and carefully-developed tools, including AI tools, could help to identify and mitigate these and other biases in many everyday work and life situations. As one example, a recent article by
Zieminski highlighted how use of data and AI tools could help to improve objectivity in business decision-making and reduce friction in prioritizing product features. 41
4b. Problem
When developing an AI-based tool, biases can be introduced, worsened, or mitigated in steps 2-4: data sourcing, data labeling (by humans or AI models), and model building. At best, an AI tool can only be as good and as fair as:
the diversity of society represented in the data,
the priorities for the tool’s design,
developers’ awareness and abilities to identify and address bias risks.
People build tool designs and models with the data, priorities, and risks in mind. Datasets tend to be biased because our society (from which data is drawn) is biased. 42 Without care in sourcing, selecting, and handling data for use in AI, biased AI tools will result, and will reinforce and worsen existing harmful biases in our society.
4c. Status
Studies and stories abound which show that many AI models are biased. This was the case even before generative AI tools broke through to the mainstream. These biases can cause direct, concrete, and immediate harm, such as in medicine. Classic examples include how heart attack symptoms in women differ from what men experience, or how women are often excluded from medical trials, even on treatments for diseases more common to women.
“A [2021] study by the Berkeley Haas Center for Equity, Gender and Leadership analysed 133 AI systems across different industries and found that about 44 per cent of them showed gender bias, and 25 per cent exhibited both gender and racial bias.”
“When women use some AI-powered systems to diagnose illnesses, they often receive inaccurate answers, because the AI is not aware of symptoms that may present differently in women.”43
At their worst, AI tools can reinforce and worsen existing harmful biases in society 444546 . Examples:
Machine learning vision tools fail to recognize people with darker skin 47
Generative AI creates only pictures of white men in suits when asked to picture a CEO 48
Predictive policing algorithms show high racial disparities 49
Some efforts to date in using AI to make decisions more objective (such as hiring) have backfired. (Example: Amazon’s 2014 experiment with AI-guided hiring was halted in 2018 after they discovered that the tool’s design and training reflected historical biases. 50)
Detecting and fixing biases is not easy. 51 Lack of diversity in AI development jobs remains a significant gap but is slowly improving. 52
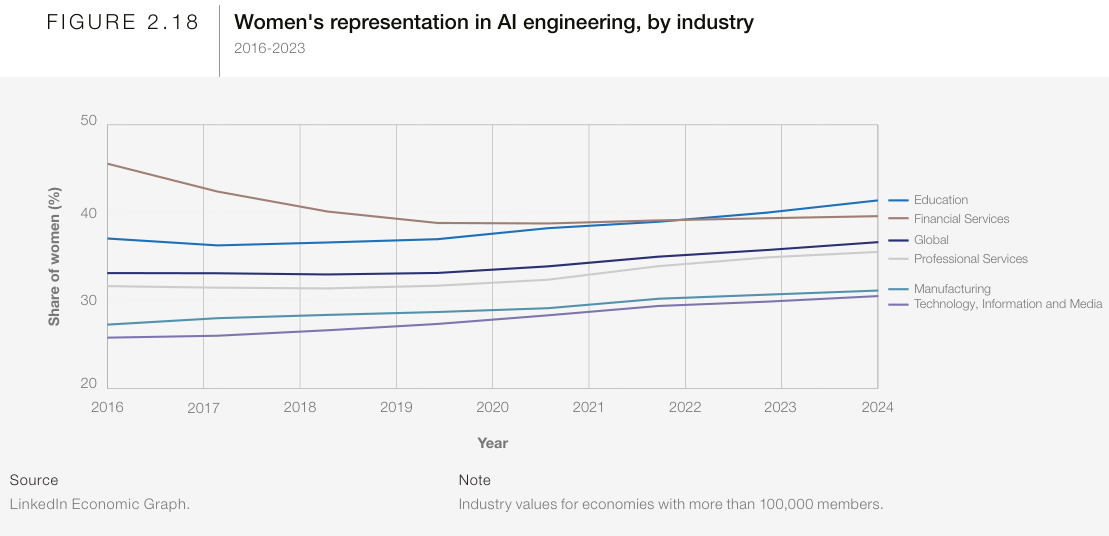
“The share of women with AI Engineering skills has increased overall since 2016. Yet, female AI Engineering talent as a share of the overall industry workforce has a smaller industry presence than male talent in 2023 – and the differences are most pronounced in Education and in Technology, Information, and Media. However, the sectors with the most significant increases in female concentration over time are Technology, Information and Media, followed by Professional Services and Financial Services (Figure 2.18).” 53
However, work is ongoing and some progress is being made. (Example: Textio’s inclusive recruiting and management tools 54; the Zizi project for diversity in images 5556)
“Existing AI tools owned by large companies have difficulty identifying non-binary individuals in their training data and therefore are unable to generate depictions of non-gender-conforming people. This is not the fault of the AI – the machine learning will learn what it is directed to learn. Jake Elwes’s Zizi Project is a great example of utilizing AI for this end.” [from 56]
References for Concern 4: 37-56 inline above plus 57.
Some people question the harm of AI companies harvesting or scraping data to build generative tools that “we all” can use, sometimes even “for free”. Like other aspects of ethics, there are pros and cons for human use of AI tools (step 5 in the diagram).
5a. Opportunity
A common argument for allowing AI companies to freely use the world’s data is that “we all” will benefit from what altruistic non-profits could do with it.
AI-based tools can potentially help people be more efficient in their work, enable them to create and grow businesses, or support altruistic missions. They can also offer benefits for accessibility and improving global communications. [If you’re using Substack’s “read aloud” feature to listen to this article, that’s AI-based voice cloning in action.]
AI and ML can also be used wisely and ethically to improve people’s lives in many ways. For instance, AI tools may detect lung cancer earlier(a cause that’s long been close to my heart). 58
5b. Problem
Most AI companies aren’t altruistic. They’re commercial, profit-driven enterprises. Many big companies take people’s data, images, music, videos, voices, and more, and make major money (stock value, income, or both) from AI models they train on it all. To be blunt, data scraping is theft - and often not even for noble purposes. It is “socializing the costsand privatizing the profits” [massively stealing, and then keeping the gains]. 59
And “we all” will not benefit from AI tools to the same degree. Some people’s lives and livelihoods will be severely harmed. Human creators worldwide lose potential income from selling rights to their existing works. Other people benefit, at their literal expense, from using AI tools built on their stolen work.
Making matters worse, these generative AI tools can directly deprive those creators of NEW income. People and companies who previously would have paid human creators to make a drawing, compose some music, make a video, or write an article or book can now use generative AI tools to make something “good enough” (which sometimes is, but often isn’t).
Keep in mind that even “free” tools aren’t really free. Every person who uses those AI tools (and every person on whom the AI tools are used) is giving the tool companies even more data — sometimes very personal data! — that the companies will likely use for AI training and tuning. Through interactions, feedback, and prompting sequences while using the tool, human users create computing workloads and give free data and labor to the tool companies. This is reflected by the arrows in the reference diagram, looping back from human use of the tool to data centers, data sourcing, data processing, and model building.
Many people view providing this labor and data as part of their cost for being able to use the tools (whether they are free or not). However, without knowing how AI companies will use our data, people may not know the actual price they pay. It’s not ‘informed consent’, and may not be a fair exchange of value.
5c. Status
Many observers have pointed out that when major technological changes have disrupted our societies in the past, people’s livelihoods were impacted then too, and “it worked out”. (Example: introduction of the automobile affected businesses built around horse-drawn transportation.) However, in the past, fewer people were impacted by a given shift, and folks whose livelihoods were disrupted had more time and leeway to adjust to finding a new way to make a living. That’s not the case for millions of people with this current AI wave.
Many people report that access to generative AI tools has helped to build or streamline their businesses. Several of my AISW interview guests have touted this benefit. 60
However, many people are already losing jobs and businesses to AI ‘competition’. Some AISW interview guests have reported this happening to them. AI tools which were unfairly built on stolen professional-quality work are being used to compete against them. Their businesses are withering as a result. Markets for creative works by musicians, artists, writers, and many other professions are being overrun by competing AI-generated content (e.g. Spotify and Amazon books). 616263
As one example, people who tout opportunities for voice artists or musicians to use AI suggest that they use voice cloners to make more money. A handful of voice cloning tools are ethical, and some have helped musicians revive their careers.64 However, many tools offer voices they cloned without consent, or allow users to clone anyone’s voice (not just their own). Thieves have cloned performances of voice artists and musicians without consent and made money with the AI clones, instead of the voice artist or musician they ripped off.
Scammers have also used voice cloners to create harmful “deep fakes”. 65 In other cases, people (including children) have been harmed or killed by irresponsibly developed ‘social’ tools such as Replika or Character.AI. 666768
Regulatory actions are slow, and not yet well coordinated worldwide, but progressing. This report summarized status worldwide as of April 2024. 69This site tracks progress on implementing the EU AI Act. 70 For example, on Feb. 2, the EU released new guidance on banning harmful AI uses. 71
A key gap that isn’t yet well addressed is proactively supporting the transitions of millions of people whose lives and livelihoods are being disrupted by AI. As HBR presciently noted in 2022, a month after ChatGPT was released:
“The key to adjusting is figuring out how to redesign our economic systems to fully engage the working population. That will require system solutions that don’t just shift the same tasks between people and machines.”72
The world of AI tools and ethics changes daily. Here are four suggested actions for people who want to use AI ethically and wisely and keep up with AI ethics concerns.
1. Choose your AI tools wisely.
1a. Check for certifications of responsible AI.
None are complete, and absence of an AI certification doesn’t mean a company is unethical. But knowing a company’s certification status may be useful. Examples:
Check out the providers of the tools you are using, or thinking about using. Do some web searches (real searches with traceable citations, not AI ‘overviews’) and ask questions:
Does the company clearly state whether and how they use AI? Do they share users’ data with an underlying AI cloud platform or partner?
Can the tool give citations or sources for the results it gives users? Are they legit?
Does the AI platform or tool publicly affirm their adherence to regional data protection standards? (Worth knowing even if you don’t live in one of those regions.)
What do the AI tool’s website “Terms of Use” and “Privacy Notice” say they will and won’t do with the data you put in the tool? (See this 2023 podcast by Mark Miller for plain-English explanations by a lawyer of EULAs from 10 major companies.)
Is the company transparent with users about where the training data was sourced AND how it was enriched? (Few uncertified companies share this info, but give it a try.)
Were data providers able to consent, be credited, and receive compensation (the “3Cs of creative rights”)?
Whether the company hires data workers directly or outsources to a third party, are they treated fairly?
When people use the AI tool, are there ways to prevent or detect users providing copyrighted materials or someone else’s likeness [image, voice, …]?
1c. Seek outresponsibly-developed AI tools that proactively address biases.
It’s hard for a casual user to evaluate how a tool company handles biases. It’s simply not practical for most people to assess a company’s internal development process.
But “the proof is in the pudding”. If you see or hear multiple credible reports of a tool (AI or not!) generating highly biased outputs, and you don’t see, hear, or find the company reporting how they’re addressing the problems, that’s a pretty solid indication that mitigating bias isn’t a priority.
Be thoughtful about which tools and companies you choose to allow to use your personal data - or the data of children, friends, patients, clients, colleagues, partners, or businesses. Some tips:
Before you enter detailed prompts or responses, or upload files to an AI tool, know how that data might be used to train the company’s tool - or by an AI platform or partner behind the tool.
If you post images of your creative work online, consider using one of the ‘data poisoning’ tools to protect your images (e.g. Nightshade,Glaze, or Kudurru).
3. Use [Generative] AI Tools Wisely
Many needs do not require AI or ML to be well met. Before reaching for that chosen AI-based tool, consider whether the needs could be met with a non-AI search, image repository, tool, etc. or by an original human creator. (For example, many public domain and free-to-use sources of images are readily available; the list of image sources I use is here).
If not, use the genAI tool efficiently. Learn to prompt it more effectively so that you get useful results with fewer runs. And be alert for biases in what you get from AI tools, especially generative AI tools. Not all medical advice cited by AI is based on studies that include women, and not all CEOs are white males in suits!
4. Seek out diverse voices about AI.
Expand your reading or listening beyond the uber-rich USA-based tech bros who hype AI tools for their own massive benefit! Here are 4 suggestions:
See this directory of women and nonbinary folks who write about AI and data here on Substack (currently 240+ in 37+ countries). Search the table to find writers on topics you care about (e.g. 8 on “education”). You’ll probably find people in your industry and role who are using AI & data well, and writing about how they do it!
If you prefer to read & discuss AI on LinkedIn, the table in that directory includes LinkedIn profile links. You can also follow #SheLeadsAI (contact: Anne Murphy) or Black AI Think Tank, or look for posts on #EthicalAI or #ResponsibleAI.
By using ethical genAI tools well and only when needed, we can reduce data center runtime demands and impact on our environment; minimize infringement, bias, or pollution risks; protect our privacy; avoid contributing to harming creators and data workers; and maybe even save time and money.
What questions do you have about finding and using AI tools ethically and responsibly?
Many AI tool users may be unaware of the risks they are taking with unethical tools, such as loss of privacy, copyright infringement, or unintentionally generating biased or harmful content. One goal of this article is to help more people become aware of the ethical risks and what they can do to use AI safely. If you enjoyed this article, please add a heart, share, restack, or post a Note! This helps others to find the article, and it lets me know you value this work.
6 'P's in AI Pods (AI6P) is a 100% reader-supported publication. (No ads, no affiliate links, no paywalls on new posts). All new posts are FREE to read and listen to. To automatically receive new AI6P posts and support this work on AI ethics, consider becoming a subscriber(it’s free)!
One-time tips or voluntary donations via paid subscriptions are always welcome and appreciated, too 😊
Special offer: In honor of International Women’s History Month and my first full year on Substack, as a thank you to my readers, I’m offering a 25% discount for life on all monthly or annual paid subscriptions started by March 31, 2025. Use this Subscribe link or the button above to redeem!
Disclaimer: This content is for informational purposes only and does not and should not be considered professional advice. Information is current at the time of publication but may become outdated. Please verify details before relying on it. All content, downloads, and services provided through 6 'P's in AI Pods (AI6P)publication are subject to my Publisher Terms available here. By using this content you agree to my Publisher Terms.
Explanation of diagram: Here’s a quick overview on these 5 steps in delivering AI tools. AI companies:
Build huge, high-capacity data centers. (Or contract with a company that has these data centers.)
Acquire large volumes of data for ‘training’ AI models in those data centers. Data sources include: ‘scraping’ the public web; ‘data brokers’ who collect and sell our data; licensing data from other companies (such as book publishers or music labels); and people who already use their tools.
Process the data to get it ready to use for AI. (For instance, a song might be labeled with its genre, or a video might be labeled as offensive.) This is done partly by human ‘data workers’, partly by using AI models for labeling.
Have AI developers build models with the data, evaluate them for accuracy and fairness, and tune them.
Offer AI tools with features that use these models, and collect more data on how people use the tool and features.
As shown in the diagram, ethical concerns arise in each of these 5 steps.
Environment: “Reducing the Carbon Impact of Generative AI Inference (today and in 2035)”, by Andrew A Chien, Liuzixuan Lin, Hai Nguyen, Varsha Rao, Tristan Sharma, Rajini Wijayawardana. ACM Digital Library (open access), HotCarbon '23: Proceedings of the 2nd Workshop on Sustainable Computer Systems, Article No.: 11, Pages 1 - 7, 2023-08-02.
1. The Dunning-Kruger Effect, 2. Confirmation Bias, 3. Self-Serving Bias, 4. The Curse of Knowledge and Hindsight Bias, 5. Optimism/Pessimism Bias, 6. The Sunk Cost Fallacy, 7. Negativity Bias, 8. The Decline Bias (a.k.a. Declinism), 9. The Backfire Effect, 10. The Fundamental Attribution Error, 11. In-Group Bias, 12. The Forer Effect (a.k.a. The Barnum Effect)
Biases in society: “Project Implicit” and “Implicit Association Test for Social Attitudes”, Harvard University. Offers 18 different free self-tests covering age, gender, and many types of affinity biases including color, ethnicity, race, religion, and sexual identity:
Biases in society and AI: “How AI could perpetuate racism, sexism and other biases in society”, by Brianna Scott, Ailsa Chang, Jeanette Woods / NPR (All Things Considered), 2023-07-19
Biases in AI tools: “Measuring Racial Discrimination in Algorithms”, by David Arnold, Will S. Dobbie & Peter Hull / National Bureau of Economic Research Working Paper 28222, Jan. 2021. DOI 10.3386/w28222
Overview: “AI—The good, the bad, and the scary”, by Florence Gonsalves, Jama Green, Alex Parrish, Tonia Moxley, Chelsea Seeber, and Ashley Williamson / Virginia Tech Engineer | Fall 2023
“… initiatives highlight the need for companies to consider these factors when developing, maintaining, using, and deploying an AI-based product:
Taking necessary steps to prevent harm before and after deploying a product.
Taking preventative measures to detect, deter, and halt AI-related impersonation, fraud, child sexual abuse material, and non-consensual intimate imagery.
Avoiding deceptive claims about AI tools that result in people losing money or put users at risk of harm.
Ensuring privacy and security by default.
[Note: if this FTC link stops working or the page content disappears, let me know - I saved a copy.]
Impact on Lives and Livelihoods: “ChatGPT and How AI Disrupts Industries”, by Ajay Agrawal, Joshua Gans and Avi Goldfarb / Harvard Business Review, 2022-12-12









![4 pillars of ethical genAI for music [Unfair use? series, Part 2] 🗣️](https://substackcdn.com/image/fetch/$s_!nMjV!,w_140,h_140,c_fill,f_webp,q_auto:good,fl_progressive:steep,g_auto/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2F69ebdded-e557-42fc-87a8-fb959b309e2e_1730x1170.png)








![AI Ventriloquism: Send in the clones [Unfair use? series, Part 3] 🗣️](https://substackcdn.com/image/fetch/$s_!3noV!,w_140,h_140,c_fill,f_webp,q_auto:good,fl_progressive:steep,g_auto/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2F7bc400e7-7489-4c1a-a4f5-5df0b4d21fc7_1990x1100.png)
![Ethical AI Standards by Region [PART 2 Supplement in "Unfair use?" series]](https://substackcdn.com/image/fetch/$s_!n_ka!,w_140,h_140,c_fill,f_webp,q_auto:good,fl_progressive:steep,g_auto/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2F2433d7cf-2fc3-49fd-af0f-8fbd8dfe33ac_3362x1530.jpeg)
This article covers geographic locations of data centers and localized water usage issues: https://www.theguardian.com/environment/2025/apr/09/big-tech-datacentres-water (thanks to Janet Salmons for the link)
New article by Masheika Allgood on water use: https://open.substack.com/pub/eatyourfrog/p/there-isnt-enough-water-for-all-of