




Introduction - Samuel Theophilus
This post is part of our AI6P interview series on “AI, Software, and Wetware”. Our guests share their experiences with using AI, and how they feel about AI using their data and content.
This interview is available as an audio recording (embedded here in the post, and later in our AI6P external podcasts). This post includes the full, human-edited transcript. (If it doesn’t fit in your email client, click here to read the whole post online.)
Note: In this article series, “AI” means artificial intelligence and spans classical statistical methods, data analytics, machine learning, generative AI, and other non-generative AI. See this Glossary and “AI Fundamentals #01: What is Artificial Intelligence?” for reference.

Interview - Samuel Theophilus (Nnitiwe)
Karen: I am delighted to welcome Nnitiwe from Nigeria as my guest for “AI, Software, and Wetware”. Nnitiwe, thank you so much for joining me on this interview! Please tell us about yourself, who you are, and what you do.
Nnitiwe: Thank you. Thank you for having me, Karen. I am Samuel Theophilus, and I am an AI and data engineer with over six years of experience. I have consulted with core companies and worked for ENG non-governmental organizations, both in Nigeria and abroad. I basically integrate AI solutions into business processes, so automating or SOPs.
And also I have had the privilege to mentor data professionals, AI enthusiasts into both complete beginners, non-technical professionals, and also technical professionals who are trying to transition from software development to AI, data science, data engineering.
And I also currently run an AI blog. And basically that’s a blog where I share my experience or expertise working with how to build AI tools, integrate AI into business solutions, and then with a lot of hands-on experience for readers.
So currently that’s a high level of what I do technically. I hope that addresses the question.
Karen: Yes, very much. You also mentioned that you worked on some organizations with societal impact, and I thought that was very interesting.
Nnitiwe: Here in Nigeria I’ve worked with climate change NGOs [non-governmental organizations]. And I’ve also partnered with a humanitarian body to build feedback response solutions to track complaints from beneficiaries after humanitarian projects, or after distributions of aid and resources to build AI pod solutions to help simplify the process of tracking feedback and tracking some of the complaints. These are some of the projects I’ve done in the humanitarian space. And also with a crime-focused NGO that tracks organized crime. So tracking the media for crime reports, basically indexing, tracking the media and also helping the NGO to be on top, automating a lot of their monitoring activities. Yes, so that’s a high level of what I’ve done with respect to humanitarian NGOs.
Karen: It’s really great to hear about that. That’s very commendable. So appreciate that you’re doing that. That’s some amazing work. And it’s great that your AI blog is being widely read as well. 59 countries is great, and we’ll include a link to that in this article when we publish the interview.
Can you tell me a little bit about your level of experience with AI and machine learning and analytics? You talked a little bit about your years of experience. Sounds like you’ve used it professionally;. Maybe you’ve also used it personally and studied the technology.
Nnitiwe: Yes. I actually have a technical background. I have a computer science degree, so pending even before the ChatGPT era, before the LLM, and the breakthrough in AI recently that generative ai. I’ve worked with tools like TensorFlow, PyTorch, scikit-learn. I have been in the data science space. I also worked on research, as a matter of fact. In 2019, I had a publication on IEEE where I worked on an automated cataract detection solution using neural networks. So I have had some experience with AI. I also have worked with tools like AWS cloud platforms.
I’ve worked in various roles: machine learning engineer, ML engineering, and also data engineering roles. So I have the technical experience with the cloud solutions as well as writing code as building trainers, training models, fine tuning models, and also integrating AI-powered APIs. So I have mainly focused on computer vision and natural language processing.
And I’ve collaborated with startups and remote companies on various projects from precision farming down to digital twin projects, computer vision projects.
Example, for the precision farming project: the objective was to try to optimize the application of herbicides on hectares, on farmland.And basically what we did was to build computer vision models that would detect weeds on auto photos. Drone images are captured of large farmlands, and then these images are now processed, and then we detect weeds on the farm.
And then, after detection, this weed is now passed through the data pipeline and sent back to the startup. And the startup is using this detection to optimize the application of herbicides so that when spraying, when applying these herbicides, the nozzles of these herbicides are only activated at the point where weeds are detected. And this reduced application by 60%.
So this is an example of a practical application of AI long before ChatGPT. So in summary, yes, I’ve had some technical experience with AI for some time now.
Karen: Yeah, it’s pretty common nowadays when people talk about AI, what they really mean is generative AI. And a lot of people just don’t realize that there are all these other machine learning applications that we’ve had for years, very practical solutions to practical problems. And I think that’s really great to hear. So I’m curious, you mentioned using the OpenAI API. Do you use any of the large language models for research, or for learning, or for any other purposes in your work?
Nnitiwe: Okay. Yes. So besides the OpenAI API, I also work with Claude. Yes. When it comes to LLMs, I don’t like to stick to just one. So I use Grok. I use Claude. I use DeepSeek and Gemini as well. And then also I work with NotebookLM, depending on the task at hand.
So when I’m trying to like research or maybe just go through a number of materials, just to understand a high level, sometimes I like working with Notebook LM because it provides a very good way to digest a lot of content from PDFs, links, and so on. So I use that when I want to ingest or just basically go high level into a lot of resources to see what I want to dive deeper into.
I also use tools like Napkin. As a technical writer, I love to create visualizations using Napkin. On my blog, you get to see a lot of visualizations, cool graphics, flow diagrams that I have generated with Napkin. So it helps me to be able to speed up that process. So that’s one very good use of Napkin.
Another tool I work with, for fun, sometimes I use Whisk. So Whisk is a Google AI tool, and it just helps you create not just comics, but if you’re interested in entertainment, whether it’s studio animations or videos or static images. So Whisk is also a tool I use and play with from time to time. These are some of the tools I work with.
Karen: I’d love to hear a little bit more about your I EEE paper. I think you said it was on deep learning for medical image analysis. I had written a short article earlier this year. There’s a company called Annalise.ai in Australia, and they were using AI to improve the accuracy of diagnosing lung cancer on chest x-rays, which is something I’m really interested in. Could you tell us a little bit more about your paper and how you used deep learning for the medical image analysis?
Nnitiwe: Okay. Yes. So for the medical image analysis, the goal of the project was to be able to use AI to minimize, because even though cataract is a treatable disease, it was meant to be a foundation. Because there are a lot of eye diseases or eye issues that, if not treated on time, can lead to total complete blindness. And in Nigeria, especially with the developing healthcare, it still has a lot to do, to get to a place where healthcare is quite acceptable. That was what drove the project.
So my dad is actually an ophthalmologist and I worked with him to just get an idea on this project. And basically what this research was about was using AI in 2017, 2018, to diagnose eye images.
We have a collection of eye images, right? And then you use AI to detect if it has traces of cataracts in that eye image or not. And then we achieved a good level of accuracy at least, and it was published.
I’m sure now a lot of research has been done. The last time I checked, I think we had about 23 citations. But the idea is to be able to grow into a point where fundus images in healthcare are used to do a lot of diagnosis to detect retinopathy, traces of retinopathy, diabetic retinopathy, traces of glaucoma, and the rest.
The idea was to be able to build the project to a point where you can detect these defects early so that people in rural areas can know, can be aware of their health challenges, and then seek medical attention in time. So that’s what the project was about and it was published and currently it has over 20 citations.
Karen: Oh, very nice. Yeah. I love hearing about projects like that where we’re using machine learning to solve problems and to actually help things and make the world better. So I love that application.
You mentioned some of the LLMs that you use. Are there any that you use for personal or professional tasks or just for fun writing or music or art or social media, things like that?
Nnitiwe: Yeah, whenever I’m trying to play with video generation for fun, I use Whisk. And then I’ve worked with Flow as well. Flow uses Google’s Veo3 behind the scenes. So I’ve used that to generate short film clips for fun. And then you have Suno. I haven’t really created, but I’ve seen Suno in play. But mostly it is Whisk and then Google’s Flow, which is basically a short film creation tool. So these are some of the tools.
And then also ElevenLabs. So I’ve played with ElevenLabs for voice generation and then also, yeah, so these are some of the examples of AI tools I’ve worked with.
Karen: With ElevenLabs, did you try to clone your own voice?
Nnitiwe: I’m aware of the feature, but I didn’t clone my voice. So I’ve actually tried to use Nigerian and Nigerian-themed voices on ElevenLabs. I know ElevenLabs has a voice library. I’ve worked with the Nigerian libraries, but I haven’t cloned my voice.
Karen: Oh, okay. I’m curious. I know a few people that have tried it. One was quite happy with it and used it for a while on her Substack blog and in her podcast. And then another said it felt like it was in the uncanny valley and didn’t like the sound. It sounded like him to me, but he did not like it himself. So I was just curious if you had tried it.
Nnitiwe: Yes. I think the reason why, personally, I haven’t tried it is because I feel like it’s too perfect. Except maybe changes have been made. But if you look at the voice generation by Google, when you use NotebookLM to generate the podcasts, it feels more natural. That is my personal opinion. When you get to hear things, even the pauses, even you get the flow, it feels more natural. So maybe if Google had a clone tool, I might have considered it, because I felt that was more natural.
So ElevenLabs is quite okay, but I think one of the reasons was it’s going to be too perfect. Or it wouldn’t be a very good representation of me, let me put it that way. Maybe that’s one of the things that slaked my desire to use it to clone my voice, let me put it that way.
Karen: I’d like to hear if you have a specific story on how you’ve used a tool that included AI or machine learning features. I’m curious about what your thoughts are on how the AI features of those tools worked for you or didn’t. So basically what went well and what didn’t go so well with your project.
Nnitiwe: Okay. Yes. So like I started sharing earlier, I worked with the humanitarian NGO to build a feedback system that tried to track complaints. On this project, one of the functionalities that was required was building an interface that could handle voice, images, videos, and text as well. So irrespective of what the user sends, a video, then the AI should be able to handle that. If sends the text or on audio, it should be able to automatically handle all those inputs. I worked with Google because so far I think Google’s AI speech library does a good job when it comes to handle Nigerian, maybe ‘cause of their large user base and their presence in the Nigerian space as well. So it has very good understanding of the local languages here, the Hausa, the Igbo, Yoruba, and some of these other languages.
So I worked with Google’s speech to text. There’s this speech to text API. And then the issue I faced was that it struggled to detect the language. Because the idea is if you receive an audio, in order to be able to handle it properly, you need to first detect what language is being spoken, so that you can transcribe that into the appropriate text.
So if it fails to detect the language spoken, it wouldn’t get the job done. So sometimes while testing, I discovered it failed. A lot of times it’s failed, and maybe because the specific models that are available for that particular function were not very rich in local language, that were not very trained in local languages. So it worked very fine with English, irrespective of your intonation, your accent. But when it comes to Hausa, Igbo, Yoruba, it struggled. So that’s one of the issues. And then I had to implement a fallback so that it handles it via text if it fails the checks.
So that was one way it was limited, but it was very good. It was interesting to see how it was able to generate when it comes to text, being able to generate, because I integrated OpenAI’s API as well. And when it comes to text, it handled some of this. It handled translation and text generation very well, like almost a hundred percent. It rarely failed. But when it comes to the text, and I think that’s because in Nigeria, like I said, one of the issues we have is the index. There’s poor indexing of data, whether it’s text, video, audio. There needs to be an improvement, or we need to take that more seriously, so it’s improvement in that area. I believe that AI solutions powered by data, of course, would improve the ability to detect and handle local text.
Karen: Yeah, that sounds like a really cool project. Language is so important and it sounds like you were able to get a really high level of accuracy on that, which is awesome.
Aside from this feedback agent project, could you have any examples of times that you used an AI tool? Maybe one example of when an AI tool worked well for you and one of when it didn’t work well for you? And this is just using the tool as a normal user, not as a developer.
Nnitiwe: Okay. As a user, I use Flow. That’s another example where there were some limitations. So Google V3, of course, one of the best performing image generation models of recent times. But it struggled with character consistency. And it’s not just a Google V3 issue. And I think generally until the recent Nano Banana release, a lot of models have struggled with character consistency.
So when you are trying to generate a video, especially different frames, a lot of AI video generation tools have eight seconds, 16 seconds a window for generating this particular clip. So in order to generate a short film, you need to be able to combine a lot of short clips or extend. But one issue I faced working with these tools, Pika and the rest, is when combining or extending, you have character inconsistency because you are generating these with prompts. And even when you use image references it’s good, but it’s not very strong. So that’s one of the mutations, especially even with Flow, it does the best so far, but it’s still struggled with that. So hopefully with Nano Banana, the progress or character consistency in Nano Banana, I believe we should be expecting some improvements in the video version of individual generation with tools like view and rest. But that was one of the issues I had while using AI tools, where I didn’t really do what I wanted to do.
Karen: Thanks for sharing that story. I’m wondering if you have avoided using AI-based tools for some things or for anything. Could you share an example of when you’ve avoided an AI tool, and why you chose not to use it for that?
Nnitiwe: Okay. Yeah. So I love to be in control of my creative process. So most times I avoid AI tools at the initial phases of my work. Even with technical writing, I don’t just go to maybe ChatGPT or Claude or Gemini and then type just “Write this article for me”. No, I structure. I pick my theme, the topic, and what I want to discuss. I draft the initial piece of this article. And then just use AI to critique, to get additional points of view and see if I’ve missed anything, if there’s anything I need to add to make it more compelling.
At the end of the day, what I’m trying to communicate is still original to me, even though I might use AI to do some grammar checks and rest. These are the areas where I try to avoid AI tools to implement that. Inasmuch as I agree that AI can be integrated to boost productivity, I also try to be conscious of the areas I automate. For instance, I don’t see myself automating my communication pipeline. I don’t see myself implementing an email automated responder because I feel it defeats the points. So I wouldn’t use that. So I’ve not implemented that. I want to be able to check my emails, understand, be up to speed of the conversations, and be in control of the response and things like that. So even when AI is able to generate smart responses, I don’t want a situation whereby I miss the flow of conversation because I didn’t read the email, and AI just automatically responded.
So once I have the draft emails, when I have what I have to communicate, and then just use AI to maybe refine. Are there tech grammar adjustments? Or are there things I need I didn’t cover, things I missed that I can just include? So these are areas I use AI while working to stay in control of my creative process and in control of whatever solutions or work.
Even when it comes to code as well. I don’t vibe code. I use AI to generate functions, mainly after I have clearly designed the pipeline, what I want to be done.
So even when AI generates pieces of whatever type of solution or whatever I’m working on, I still vet and validate the results before integrating them into the overall solution.
Karen: Yeah, that’s definitely wise to check it because it can generate some strange things. So which tool do you prefer when you’re writing code or for helping you to validate your code?
Nnitiwe: Okay, so for tools I like, I prefer Claude. I’ve noticed that Claude has high accuracy generating executable code. So that’s my go-to when it comes to code. But sometimes when debugging, I work with ChatGPT. But for generation, Claude has high success rates of generating executable code. When it comes to blogging or fine tuning, I use ChatGPT to research themes and just do some research.
So I use a lot of these tools. And then based on the response, if I’m not comfortable with the response, sometimes I try a different tool. I’m not fixed to one. I just try to use that and then see if that aligns to what I want. And then if I like the response and then I decide to pick it or discard it as well.
Karen: Yeah. You’ve got quite a toolbox there with a lot of different AI tools in it!
Nnitiwe: Yes.
Karen: One concern that we hear a lot about nowadays is where these AI and machine learning systems get the data and the content that they train on. A lot of times they will use data that users have put into online systems or we’ve published online. And these companies are not always very transparent about how they intend to use our data when we sign up for the services.
I’m wondering how you feel about companies that use data and content for training their AI systems and tools and specifically wondering your thoughts about whether, to be an ethical company, they should be required to follow what some people call the 3Cs rule that came from CIPRI, which is Consent and Credit and Compensation to the people whose data they want to use for training.
Nnitiwe: Yes. So I am a hundred percent in support of following the 3Cs rule. Because I believe that transparency shouldn’t be optional. It should be enforced. That’s why personally I’ve tried to ensure that while building solutions, I’m making sure that solutions I’m building adhere to like GDPR and then also the NDPR [Nigerian Data Protection Regulation] regulations or policies, right?
So I believe that companies should be transparent about this data. And unfortunately when you look at some of the legal cases, they haven’t been fully transparent. For instance, when you look at, I think the first time when ChatGPT came up, there was some transparency on the sources of data or the sources of data that were trained. We got to know that okay, Common Crawl was a source. And then Wikipedia and then some other sources. But over time, most of these companies have been silent about the sources. Some maybe they don’t want their competitors to also have an edge.
But still, I believe that’s a flaw that needs to be addressed. There should be transparency with all the cases. And that’s why they had a lot of legal cases. I believe there should be transparency. And also when building, I try to ensure that I’m very careful. Most of the use cases, I use AI to handle processing, summary, extraction of data. But hardly for content generation or full process. It’s not that I’m completely against it, but these are areas where you might have these kinds of issues.
So imagine using AI for research, and then you get to use the ideas without referencing those sources. And then you push that, thinking it’s your idea, but you’re basically just taking someone’s intellectual property. So I think that these are some of the areas where some of this misuse could arise.
So I’m all for being transparent, being careful about this, the solutions you work, or how you use these AI tools. And if you must use them, embrace solutions like RAG so that you are having reference data. Even if you’re going to be sourcing solutions or sourcing ideas or responses from AI, you have reference data to work with, and not just pulling from intellectual property without traces of where this data was sourced from.
Karen: Yeah. You mentioned earlier that you were using different APIs and large language models. I’ve talked with some people that have reservations about using them when they know that they’ve been built on data that the tool companies took without consent from the people. And usually their main objection is to people using them to generate slop. But I think it’s also a concern even for other applications, where they don’t think it’s fair for companies like OpenAI or Google to profit from the data that they took without consent.
And I’m wondering if you have any concerns like that about using the OpenAI API or the Google speech to text tools? Or do you feel like the importance of those language tools outweighs those kinds of concerns in those cases?
Nnitiwe: No, I think the concerns are valid. They’re valid. For instance, if you look at ElevenLabs, I think ElevenLabs tries to structure. So, for instance, if you go to the voice library, you have a number of voices. And there’s a compensation plan for voice actors. So if you clone your voice and make it public for users to be able to work with, then you have the opportunity to earn from that. So that’s a healthy way. So I think that more companies should adopt this.
There’s also a debate on web scraping, where companies like LinkedIn believe the data on these platforms is theirs, or at least under their control, and should not be sourced. But then scraping companies on the other side pushing that these are publicly available data posted by users. And so it’s made public. So I think it’s not exactly the same debate, but it’s quite similar. When you look at these companies, they are sourcing, even when you look at legal cases, they seem to lose intellectual property, data with intellectual property concerns. So I think that should be discouraged.
Of course, it’s pulling data from authored books without compensation, without consent, without clearance. It’s wrong. And even if it doesn’t go noticed, or even if it does, I don’t support that.
But I think that when it comes to publicly available data that is common knowledge, then that doesn’t necessarily have a downside. Or will I say I’m not really against that. So when it comes to using these APIs, in the manner in which I use them mainly for text processing, I try to ensure that if I’m building a solution maybe for an organization mostly this, I complete techniques like RAG, so graph based rag or knowledge graphs. So this approach allows me to be able to tap into their own data without having to rely on public availability or rely on data source from this api.
So in that way, I’m just using these APIs as a pre-processing tool. I’m processing structural data, or processing it for semantic understanding. But yes, the substance or the knowledge is still sourced from the knowledge graph, which is mainly built as a private data source. This helps me use these tools in an ethical way. So not really breaking some of these ethical concern. But I think that those having issues with some of this misuse, they’re valid. ‘Cause I also wouldn’t want my intellectual property to just be ingested without compensation or acknowledgement. Yes.
Karen: Yeah. You mentioned transparency and that you feel like the tool providers that you’ve worked with, or looked at, have not been very transparent about sharing where the data came from. Or claiming that they got it from publicly available sources, even though in many cases that content was copyrighted even though it was publicly available.
I’m wondering, have you seen any tool provider that does this well, like that was actually upfront about where they got their data? It sounds like ElevenLabs may have had some more transparency about that, about where the voices came from.
Nnitiwe: Yeah so that’s a good example. So ElevenLabs has made efforts in that regard. And then also, even though Substack is not really an AI company, while working in Substack I can remember being asked if I want to allow my data to be included in AI training data. So that’s a good example of being transparent.
Because sometimes some companies just hide these policies in their terms and conditions. And then it’s also automatic that once your data is on this platform, we will be using it to train AI models. And you don’t really have an option to opt out or not.
I think having the option to be able to, say, “Okay, I don’t want my data to be included in the AI training data”, that’s a good one. So these are some good examples. Of course there’s a lot of room for improvement, but these are examples of what can be used.
ChatGPT, I will need to check, I can’t make a comment on whether they do that or they don’t. But it’d be good if most of these platforms have options to state if you want to include your data for training, or if you wanted to be exposed to certain tools or not. But yeah, Substack and ElevenLabs are good examples that I can think of right now.
Karen: Do you know if any of them have ever shared any demographic data about representation within the datasets that they use? For instance, there was a study, I was just talking with Rebecca Mbaya about this yesterday, and I thought it was like 4% of the data that went into ChatGPT came from the global south, but I think she said it was actually more like 2%. So it’s quite unbalanced in that way. But I haven’t seen much as far as any of the providers that are doing really well with getting balanced data sets. I’m wondering if you’ve heard of any.
Nnitiwe: I can’t recall that. It’s very possible. Maybe I’ve gotten something like that in my mailbox, but I can’t really recall going through any documents or any reports that highlight that information.
Karen: Yeah. The only one I’ve heard of that might be close is Mistral Le Chat. They just trained a model, and I think they trained it on over a thousand different languages. I’m not sure what the geographic representation of those languages is. But at least they were making an effort to support more languages, not just Western English.
Nnitiwe: That’s a step in the right direction.
Karen: Yep. So when you worked with building AI-based tools or systems, can you share anything about where the data came from, and how that data was obtained?
Nnitiwe: Okay. Yes. I’ll use as an example the crime watch data that was used. We pulled public news articles we traced with reports on crime. Since it’s in Nigeria, monitoring news reports on organized crime news here in Nigeria. And then we built data structures to monitor and then extract on a daily basis any news, any crime related article sources. After analysis, whatever we get from the process, that’s the structured data or structured outputs extracted from this analysis after identifying the kinds of crimes that were reported, any key attributes, the entities. So all these were indexed and attributed.
We used technologies like rag to be able to implement knowledge graphs that made it easy to be able to trace back. So for every insight, when you query the solution, every result comes with the source. So it’s very easy to identify and also crosscheck this report from the originating news source. This is an example of how data was sourced for a particular project, and also how we maintain, that’s not building solutions that will suffer from hallucination.
Karen: That sounds like a good approach, and the way that you were processing the data and obtaining the data sounds very straightforward. That sounds good.
When we think about our roles as consumers and members of the public, our personal data and content has probably been used by some sort of an AI-based tool or system. Do you know of any cases that you could share, obviously without disclosing any sensitive personal information?
Nnitiwe: When it comes to recommendations, I would say it almost feels like a conspiracy. You get these reports that some social platforms use your phone mic, and then actively monitoring your activity, to be able to recommend content or recommend marketing. Mainly for marketing purposes, right? I’ve seen a lot of persons, and sometimes I felt that way as well, where you discuss something now, and then a few minutes or few hours later, you start seeing it pop up on your screen. You start seeing ads related to what you just spoke about, pop up on your screen. So I try to be slow to jump on that idea that it’s actually actively something else. Maybe it’s purely coincidental. But also it’s a growing concern.
For marketing reasons, I think in recent years you will have noted that companies like Apple had restrictions for Facebook, on how Facebook was going to use data from Apple users. And it’s led to a lot of changes in the way marketing was handled and things like that. I think sometimes in an attempt to process data or analyze data for marketing, to optimize marketing experience, to optimize a personal experience sometimes they could tap into personalized activities that might be sensitive and could be abused. So like scrolling time, the kind of content you like. And then also, even though I don’t have the proof, but if there’s active listening of your mic or your conversations outside the app, then that’s not very healthy. It wouldn’t be a very good way to ingest or take in personal data. Yeah.
Karen: There was a story about a project that they actually called Active Listening, where one company was caught admitting that they use what they hear on the microphone. And they made them stop doing that.
There was something else I read earlier this year that the notifications on our phones end up sharing location tracking data with the app developers, even if we have location sharing turned off, because they track it as part of the metadata for the notifications. And that was a bit of an eyeopener. I ended up turning off all the notifications on almost all of my apps after I heard about that.
Nnitiwe: Yes, it is actually concerning. Yeah.
Karen: Yeah, that was a surprise. Do you know any company that you gave your data or content to that actually told you that they might use your information for training an AI system? Or did you get surprised by it?
Nnitiwe: Yeah, like I mentioned earlier, Substack is one of those companies, right? So Substack has clearly stated, okay. I’ve given you the option to be able to say, “Okay, approve if you want your data to be used for AI training sites.” I don’t remember using any app that explicitly asked for my consent. I can clearly remember Substack, but no other name comes to mind when it comes to explicitly asking to, asking for my personal data or training.
So in most cases I assume that it’s just handled with policies, with changes in policies. It’s automatic. Social media platforms.
Karen: Yeah. And I know the switches you’re talking about in our newsletter for allowing AI training. That is actually Substack trying to set the website so that it will tell the bots and the crawlers not to come. I don’t think Substack uses our writing to train their own models anyway. That’s more to try to stop the other bots, if someone doesn’t want their content to be crawled, to try to stop it. Of course, some of the bots don’t respect that setting anyway.
Nnitiwe: Yeah, true.
Karen: Yeah. Substack warns us about that, but there’s really nothing they can do about it.
Nnitiwe: True.
Karen: I think you had said that the safest thing is just to not post things that you wouldn’t be comfortable having shared.
Nnitiwe: Yeah, exactly. Because even when you look at before the AI training phase, if you look at the challenge with web scraping, the safest way is not to have content you’re not comfortable with. Or not use any platform that, after studying the policies, you’re not comfortable with the way they handle their data, then it’s better to completely avoid such platforms.
Even platforms like LinkedIn have not been able to stop web scrapers from accessing the data they consider private. Twitter has not been able to stop that. They can put in schemes, but these schemes are always bypassed. So it’s going to be very difficult to block or to stop. If it’s out there on the internet, then it can possibly be accessed. So it’s just best to maybe avoid platforms that you don’t think have that transparency in place because they can still use it.
Karen: Yeah. I logged into LinkedIn earlier today and I noticed they have a banner across the top of the site now saying “We’ve changed our terms and our privacy policy.” I’m going to have to go read those, see what they’re trying to do now.
Do you know if a company’s use of your personal data or your content has ever created any specific issues for you? Like a privacy concern or phishing or loss of income, anything like that?
Nnitiwe: No, I don’t have any such encounters at the moment.
Karen: Okay. That’s good. Let’s hope it stays that way, right?
Nnitiwe: I think because of the challenges with scams, I really try to just keep my data off most of these platforms as much as I can. Even when I’m signing up, I have emails I use to sign up on sites I’m not very comfortable with, so that I isolate any possible data breach or things like that. I don’t have any such issues.
Karen: Yeah. That’s good. Alright, last question and then we can talk about anything else that you want. You talked about transparency and trust earlier. I think public distrust of AI and tech companies has been growing. And in a way that’s good, because it means that we’re more aware of what they’re doing and we’re saying, “Hey, wait, we’re not happy about that.”
Nnitiwe: Yeah.
Karen: Is there one thing that you think the AI companies could do that would help to earn and to keep your trust? And do you have specific ideas on how they could do that?
Nnitiwe: Yes. So I think that’s a very good question. When you look at transparency, I think the first step would be to look at what some of the AI companies are doing right? And then hope that will encourage others to adopt that. For instance, when it comes to compensation, I know not every company would be able to adopt the model. Not every AI organization can be able to do that.
But I think that there needs to be more credit. when you look at large language models now, they have improved compared to two, three years back, to an extent. You have more references, especially when it comes to public websites. I think the issue is when it comes to intellectual property, you don’t really see that being referenced from books or some of these things. But when it comes to public data, there’s some improvement with references that are pulled from public websites. So I would say there should be more of such.
And then when it comes to transparency of data used for training, there should be more transparency as well. So there should be just like if you go to Wikipedia. I was working on an article on land usage to check, just read up a little about the GPT-3. And you can see clearly how the data used for training was outlined. You get the percentages and then you also can say, “Okay, Common Crawl was used. This was used.”
So there should be more transparency. And even when companies might claim they want to, they don’t really want to make things open because they want to have an edge over competition. I think that there’s still room to be able to compete. Protect your competitive advantage while still making your sources clear for users.
My personal opinion is that one of the reasons why it might be difficult to have the sources clear is because that will create more room for accountability and will make it easy for court cases. Because if I see my data being used and I didn’t approve, I don’t want that, then I can easily sue you for that.
So I think that’s one area that there should be more transparency, maybe an index, like a catalog of all sources used. And then just having that clearly profiled so that users just understand what data they’re working on, or at least what sources they are building on.
Karen: Yeah, that sounds like a good vision. And the question I think then is how do we get there? Do you know of any standards in Nigeria or any initiatives that are trying to motivate companies to do this? Or are there maybe social pressures for companies to comply with standards from other regions like the European Union AI Act or GDPR?
Nnitiwe: Yes. So in Nigeria, currently we have the Nigerian data protection and commission. So that’s the body that regulates or that enforces data privacy and most of this. So there are currently plans to enforce and encourage companies, data processors, data controllers, to adhere to these policies. This year there was an African data conference, and it was hosted in Nigeria. Representative from Kenya at other parts of Africa. And I was privileged to attend the conference. And basically this was one of the things that were discussed encouraging af Nigeria, Africa to take data seriously.
Because as AI keeps making waves, it’s very important that data is protected because one very common misuse of data might not even necessarily be from these companies. Look at the abuse of AI for scams, for even inappropriate content, like adult content, and some of these things. So you see that there’s a need for sensitization for users to be careful about how data is processed. And also for companies to be careful about how their employees use data and how they expose data as well. So basically, this is the body that is actually actively pushing for these reforms and for the adopters for care in data handling in Nigeria. Hopefully there are some good policies laid out. And hopefully they should be implemented. And we would see better results in a few years to come.
Karen: Yeah, that sounds good. I’m glad that they are moving forward with that. It’s very spotty worldwide. The US is not doing great yet on it, and there’s a lot of catching up to do, and hopefully this will come together sooner than later.
So that’s my last question. Is there anything else that you would like to share with our audience?
Nnitiwe: Okay, yeah, so I think from now the only thing I want to share is, yes, I’m actively writing, so I’m very passionate about training and teaching AI and enthusiast basically. So if you look at what I have been doing over the years, basically just trying to train and help both organizations and AI enthusiasts to build careers in the AI space. So if anyone listening or reading is passionate about building their AI career. Because if you look at MIT’s recent AI study, a very shocking observation was made that 95% of AI projects at that AI pilot projects were not seen to be very successful. This is because of misalignment in use cases.
And also there’s a lot of hype and there’s a lot of energy behind integrating AI in business. There’s a lot of promises about what AI can do. When it comes to actually implementing this and having it sync with the actual workforce, in practice, many of these implementations fall short, because there is still a gap in understanding. There’s still a gap between understanding what AI can do and separating the hype from what is actually feasible, what’s practical, and yes, seeing how AI collaborates with the humans, professionals, to get work done.
So these are some of the things I really highlight. And also when it comes to implementation, I try to outline them in my blogs, in my webinars, in technical workshops. So anyone who is really interested in knowing, getting, learning more about this can check me out on my blog, and also try to follow up on some of the things I do. And I’m sure that you would find some of them insightful. and I will be very happy to also take in feedback as well.
Karen: Yes, I was very happy to come across your blog on Substack. We will have the link to that in the article so that people can find it. But it’s Nnitiwe’s AI blog, right? This is the title?
Nnitiwe: Yes.
Karen: All right. Thank you so much for making time for this interview, Nnitiwe, and best of luck to you in growing your blog.
Nnitiwe: Thank you for having me on. I really had a great time going through this.
Karen: Great. Thank you.
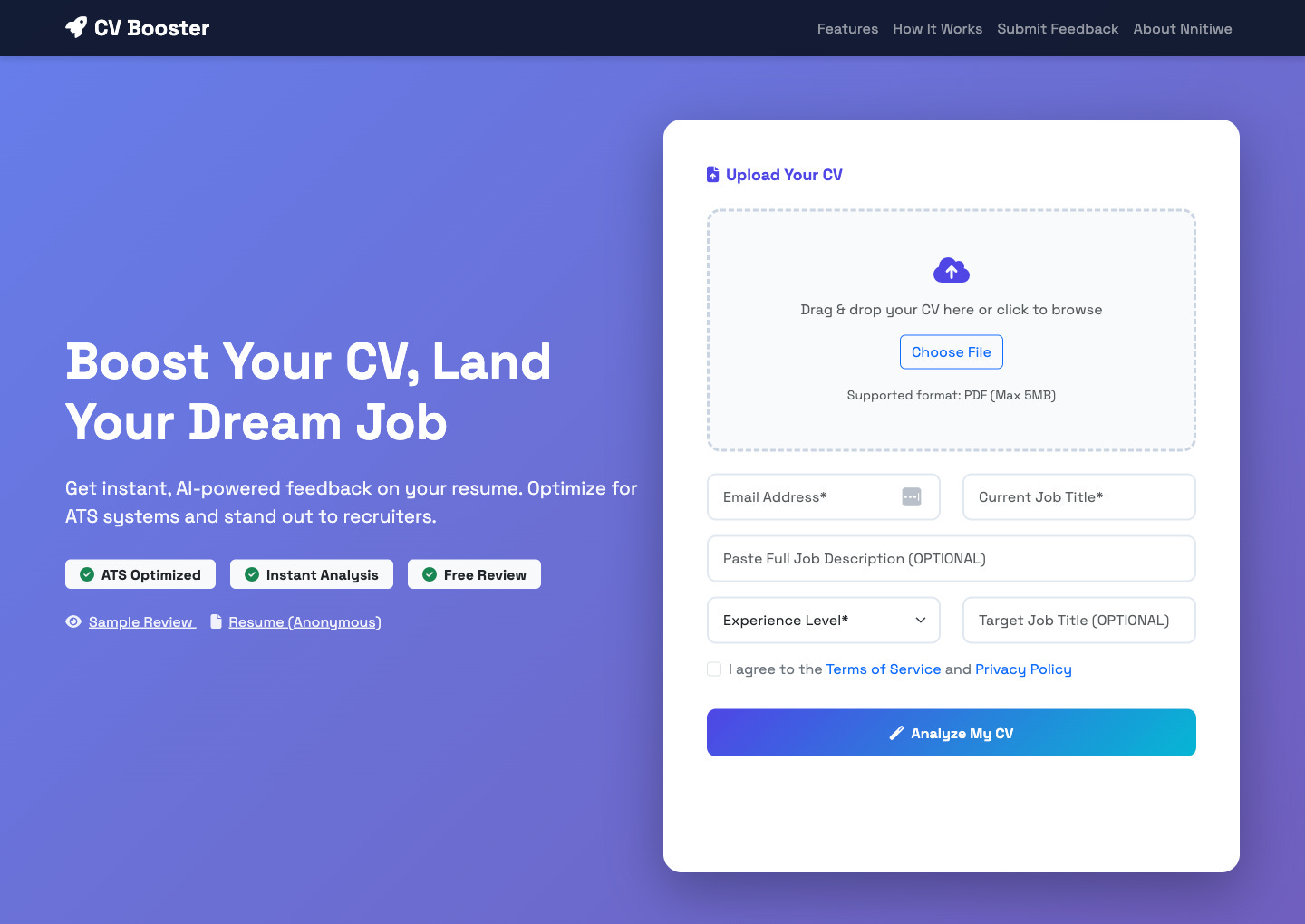
Note to readers: Shortly after we recorded this interview, Nnitiwe launched a new free tool — CVBooster. It’s an AI-powered platform that helps you analyze, refine, and optimize your CV for better job opportunities. It gives instant, personalized feedback and checks how well your CV matches specific job descriptions — all for free 🚀. He is also launching it on Product Hunt.
Try it for free at cvbooster.nnitiwe.io, and if you like it, please upvote ❤️ it on the Product Hunt page: producthunt.com/products/cv-booster! And don’t hesitate to share it with friends or colleagues who might need a CV boost ✨
Interview References and Links
Samuel Nnitiwe Theophilus website
Samuel Nnitiwe Theophilus on GitHub
Samuel Nnitiwe Theophilus on LinkedIn
Samuel Nnitiwe Theophilus on Instagram
Samuel Nnitiwe Theophilus on Substack (Nnitiwe’s AI Blog)

About this interview series and newsletter
This post is part of our AI6P interview series on “AI, Software, and Wetware”. It showcases how real people around the world are using their wetware (brains and human intelligence) with AI-based software tools, or are being affected by AI.
And we’re all being affected by AI nowadays in our daily lives, perhaps more than we realize. For some examples, see post “But I Don’t Use AI”:

We want to hear from a diverse pool of people worldwide in a variety of roles. (No technical experience with AI is required.) If you’re interested in being a featured interview guest, anonymous or with credit, please check out our guest FAQ and get in touch!
6 'P's in AI Pods (AI6P) is a 100% reader-supported publication. (No ads, no affiliate links, no paywalls on new posts). All new posts are FREE to read and listen to. To automatically receive new AI6P posts and support our work, consider becoming a subscriber (it’s free)!
Series Credits and References
Disclaimer: This content is for informational purposes only and does not and should not be considered professional advice. Information is believed to be current at the time of publication but may become outdated. Please verify details before relying on it.
All content, downloads, and services provided through 6 'P's in AI Pods (AI6P) publication are subject to the Publisher Terms available here. By using this content you agree to the Publisher Terms.
Audio Sound Effect from Pixabay
Microphone photo by Michal Czyz on Unsplash (contact Michal Czyz on LinkedIn)

Credit to CIPRI (Cultural Intellectual Property Rights Initiative®) for their “3Cs' Rule: Consent. Credit. Compensation©.”
Credit to Beth Spencer for the “Created With Human Intelligence” badge we use to reflect our commitment that content in these interviews will be human-created:

If you enjoyed this interview, my guest and I would love to have your support via a heart, share, restack, or Note! (One-time tips or voluntary donations via paid subscription are always welcome and appreciated, too 😊)

